
Scaling Accessibility: How Zero-Shot Voice Cloning Boosts Dysarthric Speech Recognition
Modern ASR can feel effortless for typical speech, but it often breaks down for dysarthria. This post summarizes a low-burden strategy: generate synthetic speech from a single short utterance to improve recognition without exhausting speakers.
Automatic Speech Recognition (ASR) systems like Whisper have revolutionized how we interact with technology. Yet, for millions of individuals with dysarthria, a motor speech disorder resulting from conditions like Parkinson’s disease, Cerebral Palsy, or ALS, these systems often fail.
The primary bottleneck is data. Dysarthric speech is highly variable, and collecting large datasets is physically exhausting for speakers who suffer from fatigue. A study by researchers from the University of Auckland and the University of Illinois Urbana-Champaign proposes a novel solution: Zero-Shot Voice Cloning. By generating synthetic training data from just a few seconds of real audio, we can significantly improve ASR performance without burdening the user.
The Challenge: Data Scarcity and Variability
Dysarthric speech is characterized by imprecise articulation, irregular pacing, and unstable phonation. Standard ASR models, trained on typical speech, struggle to map these acoustic patterns to text.
The Catch-22: To build better models, we need massive amounts of dysarthric speech data. However, asking individuals with motor speech disorders to record thousands of sentences is labor-intensive and ethically difficult due to rapid speaker fatigue.
The Solution: Low-Burden Augmentation
The researchers investigated a low-burden approach. Instead of recording hours of speech, they asked: Can we clone a speaker’s voice using only a single sentence and use that synthetic data to train the ASR?
The Methodology
- Input: A single reference utterance (average 7.2 seconds) from 8 speakers in the TORGO dataset.
- Cloning Engine: Higgs Audio V2, a foundation model capable of zero-shot voice cloning. It conditions directly on the waveform to capture dysarthria-salient cues such as irregular timing and breathiness.
- Text Prompts: Diverse prompts from the Speech Accessibility Project (SAP) to expand vocabulary coverage.
- ASR Fine-Tuning: About 15 hours of synthetic speech to fine-tune Whisper-medium.
Practical takeaway: synthetic speech scales quickly, while real recordings stay minimal and user-friendly.
Measuring Fidelity: Does it Sound Like the Speaker?
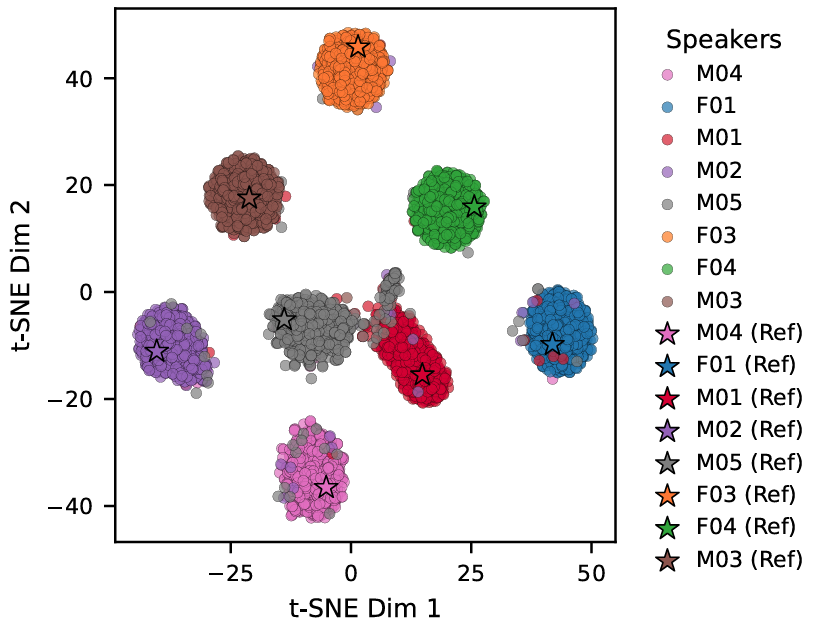
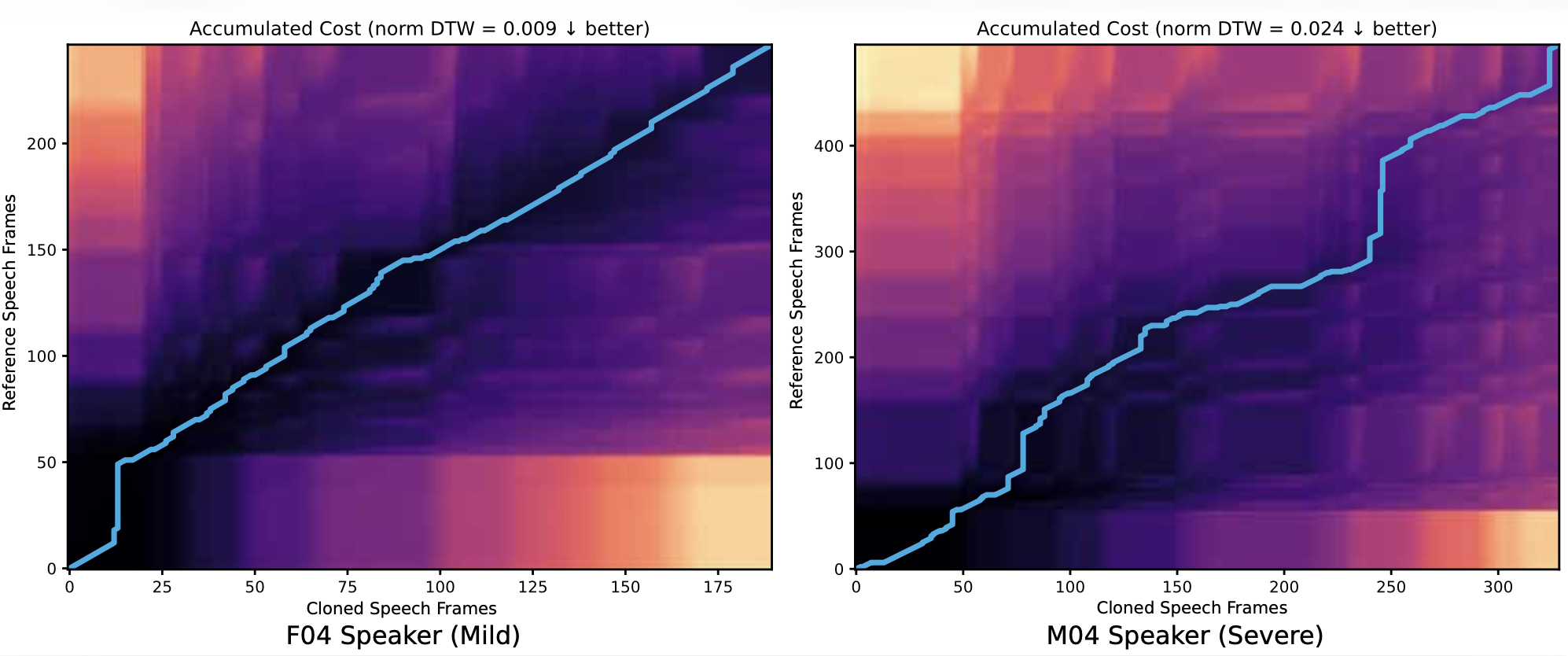
Generating speech is one thing; preserving the specific pathological characteristics of the speaker is another. The study evaluated speaker similarity using cosine similarity between embeddings.
To calculate the similarity \(s_j\) between the real embedding \(\mathbf{r}\) and the cloned embedding \(\mathbf{c}_j\):
The results showed that the cloning model successfully clustered synthetic utterances around the real speaker’s identity. However, the model struggled slightly more with severe dysarthria compared to mild cases.
Key Findings: The Force Multiplier Effect
The study evaluated performance using Word Error Rate (WER) on held-out real dysarthric speech. The results were compelling:
- Baseline (No Fine-tuning): WER = 32.96%.
- Clone-Only: Synthetic-only fine-tuning reduced WER to 28.12% (14.7% relative improvement).
- Clone + Real (Hybrid): Adding just 1.55 hours of real dysarthric speech dropped WER to 13.98%.
Performance Comparison
| Training Condition | Overall WER | Relative Improvement |
|---|---|---|
| Baseline | 32.96% | - |
| FT: Clone-only | 28.12% | 14.7% |
| FT: Clone + Real | 13.98% | 57.6% |
Conclusion
This research demonstrates that synthetic data is not just a backup. It can be a force multiplier.
By cloning a voice from a single sentence, researchers can create a robust baseline model. When combined with a tiny amount of real data, performance improves dramatically. This low-burden framework points toward ASR that can be personalized for users with severe speech disabilities without requiring exhausting recording sessions.